
Everyday at Pollicy, we publish a series of #datatips to keep audiences learning. We’ve decided to compile them in one place, for your viewing pleasure. Give us feedback on what you would like to see next!
General
Volumes of data are continuously growing every second of every minute. Data is everywhere. In order to use this data effectively, we must ensure that the entire data management and processing process is handled carefully to avoid getting spurious results. Before investing time and money into data science, you must have a plan for the entire data process. Good planning can help you capture better, richer, more accurate and more meaningful data . Here are some data tips you should consider:










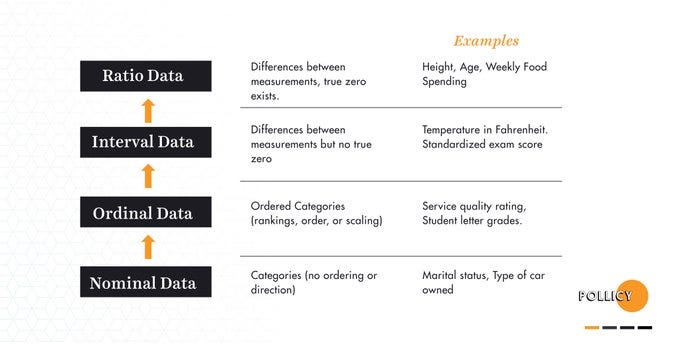
Data Visualization
One of the most effective ways to communicate your data story is to place it into a visual context with the help of maps, charts, graphs and more. About 85% of the information we process and learn is processed through vision. This makes data visualization the go-to for making any amount of data easier for the human brain to process and understand. To effectively utilize the power of data visualization, you must understand your audience, choose the right chart type, take advantage of colors and other considerations like these below:



Machine Learning
Machine learning is the data science field that is getting the most attention at the moment. When diving into the ML, you must prepare for some challenges it faces such as overfitting, operationalization, underfitting and more. The most important step in the machine learning process is the data preparation process. When preparing the data for machine learning, you must format the data to make it consistent, improve the quality of the data by handling missing values and removing other errors, perform future engineering and split the data set into a test, validation and evaluation sets.






Biases
The entire process of working with data can be painstaking and tedious, and is prone to making some common mistakes here and there. These mistakes can result from flawed data entry processes, can be deliberate, or can be the result of poorly constructed processes.
The number one cause of making wrong data decisions is “bias”. Bias happens when researchers interfere with the outcomes by relying on predetermined ideas, prejudice or influence in a certain direction. When the data process is influenced by bias, all conclusions and results are no longer representative and become incorrect. Bias in data can result from:
- survey questions that are constructed with a particular slant
- choosing a known group with a particular background to respond to surveys
- reporting data in misleading categorical groupings
- non-random selections when sampling
- systematic measurement errors.
As long as you have a clearly defined hypothesis and you have considered all the necessary assumptions, all that is left to do is have a clear line between your conceptual clarity and allowing your personal feelings to affect your analysis. Issues like publication bias, sampling bias, survivorship bias, and Simpson’s Paradox are some of the pitfalls you might encounter if you allow your intuitions to lead the data, instead of having your data lead your intuitions.







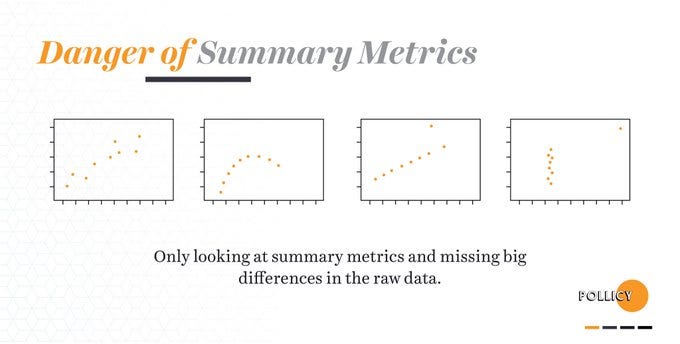
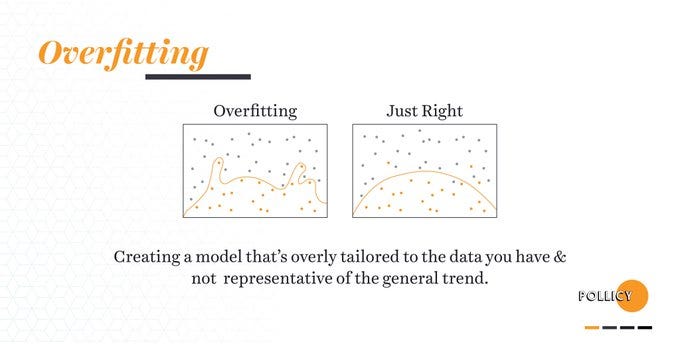

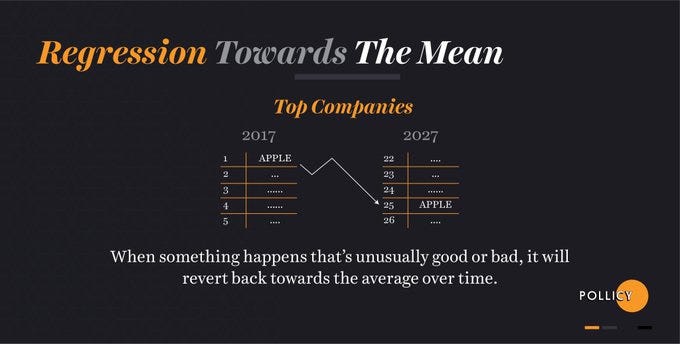


Digital Security
One of the ethical considerations of working with data is ensuring the data is kept safe and protected. However simple or complex your data set is, always think about adhering to the terms of consent set during your data collection — specifically, the confidentiality and anonymity that participants were promised. Data can be kept secure by making regular backups of files, protecting your device against malware and viruses with anti-virus software, using passwords to restrict access, using data encryption techniques and more. Before you access or collect data, you should ensure that you have all the necessary requirements for data storage in place. Other measures to consider are:



Written, compiled and conceptualized by Arthur Kakande, Communications Lead. Designs by Wilson Lukwago, Design Lead at Pollicy
